Baxter’s free funnel analysis SQL generation tool is out!

Today we’re releasing a free tool that generates multi-step funnel analysis queries in nine SQL dialects: BigQuery, Snowflake, Redshift, Spark, ClickHouse, DuckDB, PostgreSQL, MySQL, and SQLite.
It’s free, it’ll save you time and tears, and it's available here [Edit: the SQL generator is no longer available].
Give it a spin! Reach out to us if you have requests or run into issues!
Implementing funnel analysis queries across nine SQL dialects will lead you into some pretty goofy corners of SQL implementations. Stay tuned to the Baxter blog for posts about query strategies we've implemented and the SQL quirks that we made friends and enemies with along the way.
For now, let's get you situated.
The rest of this post outlines the assumptions our funnel SQL generator makes about your event data and the kinds of funnel analyses it enables.
I'm also going to share a bit about the strategies we employ and how we test them so you can be confident in their results.
Join the Baxter waitlist to partner with us as we build product analytics tools for the event data in your warehouse.
Table of Contents
- What data model do these queries require?
- What kinds of funnel analyses do these queries allow me to do?
- Nine SQL dialects, three funnel query strategies
- How do you know these are correct?
- Questions? Requests? Issues?
What data model do these queries require?
If you want these queries to work out of the box, you’ll need an events table with at least these three 3 columns:
user_id: an identifier — the type won’t actually matterevent_name: the event’s name as some textual type (TEXT,VARCHAR, etc.)event_timestamp: the time at which an event occurred as aTIMESTAMPorDATETIME-compatible type.
If your table or column names differ, you can modify them in the SQL we generate. And if you have more columns, these queries will still work. In fact, that's a pretty common scenario!
You might already have a wide table of events if:
- You use Snowplow to track your events.
- You have GA4 writing data to BigQuery.
- If you use one of Segment or Rudderstack’s data warehouse connectors.
- If you pay Heap/Amplitude/Mixpanel/Posthog to send raw event data to your warehouse.
Some companies do custom event tracking or build data pipelines that materialize event data this way, too.
For example, a row in your orders table might turn into a row in your events table. If a user with id 23 placed an order on January 22nd, 2023, you might create this row in events: 23, Order Placed, 2023-01-22 13:34:01, (various columns with order properties)
The are two primary benefits to modeling event data as a wide table with many columns:
- One data model answers many questions: you can perform a lot of common product analytics queries with this data model.
- Performance: you prevent joins by having one table with all the dimensions and metrics you want to query.
If you don’t have a table of events, you’ll need to massage your data so that it’s structured this way.
Finally, you might have more complicated predicates in your funnel steps like event_name == 'Pageview' and url_path LIKE '...'. You can modify the queries we generate with your own predicates and remain confident that the query will yield accurate multi-step funnel conversion numbers.
If you have questions or requests for improvement, please reach out!
What kinds of funnel analyses do these queries allow me to do?
You can analyze funnels…
- … with any number of steps
- … that must happen within some duration
- … where other events may happen in between each step
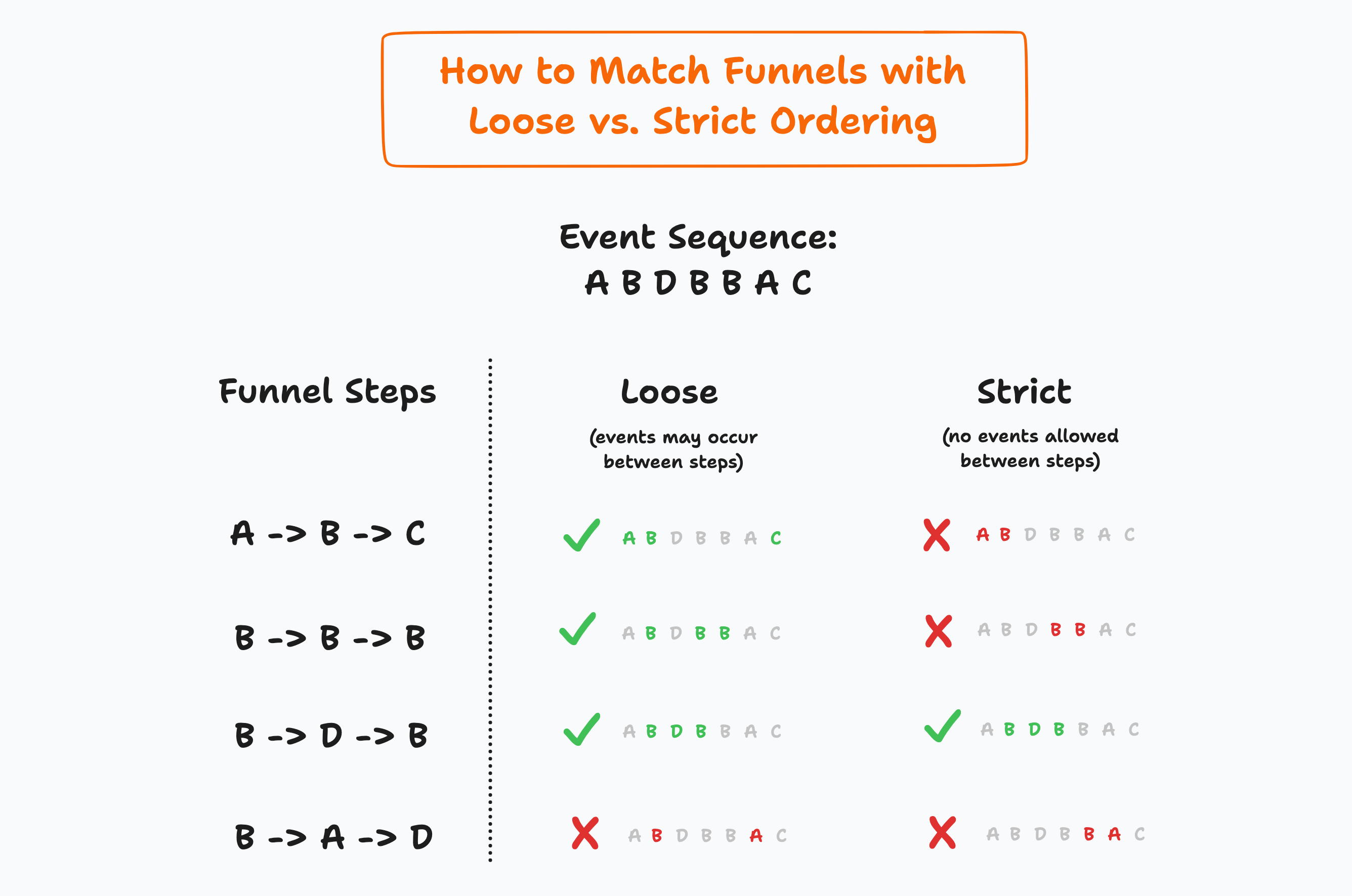
Another way to state the above is that these queries support funnel analyses with loose ordering and a total sequence time constraint.
They do not support strict ordering or a stepwise time constraint.
Credit for this terminology goes to TJ Murphy — a certifiable funnel query expert — who shared it with me some months ago. I don’t know if this language is actually formalized anywhere.
Here’s the difference between loose and strict ordering.
Here’s the difference between total sequence and stepwise time constraints.

Growth marketers, product managers, and analysts most commonly want loose ordering and a total sequence time constraint when they perform funnel analyses. That’s what our funnel query generator supports today.
Funnel queries that implement strict ordering and a stepwise time constraint are substantially different. We haven’t implemented them yet but we’ll work on it if folks are keen on it, so tell us if you are.
Nine SQL dialects, three funnel query strategies
At release we employ three funnel query strategies across nine SQL dialects.
If we don't support your SQL dialect and you'd like for us to, we want to help!
These are the strategies we employ today:
- Self-joins: this is our fallback for less full-featured dialects. We use it for Redshift and SQLite.
MATCH_RECOGNIZE: our Snowflake funnel query strategy is based onMATCH_RECOGNIZE, a powerful feature unavailable in other dialects we support.- Window functions, range frames, and regexes: we combine these techniques to implement funnel queries for every other dialect we support. (Range frame specifications might be my favorite modern SQL feature to-date.)
Right now, our goal with Baxter's funnel SQL query generator is to help users solve their immediate problem: writing a funnel analysis query that just works.
While we haven't tested the performance behind these strategies, we know with certainty that one of them scales poorly: the self-join. We'll benchmark and improve the strategies we use for each dialect over time.
If you have an approach that works particularly well for your dialect and data warehouse, we'd love to hear about it.
How do you know these are correct?
We’ve built a synthetic dataset that we run and check our queries against. We also have test harnesses that run generated queries against a data warehouse for every dialect we support.
We do a lot of automated testing!
If you come across a bug, please let us know and we’ll get it fixed promptly.
Questions? Requests? Issues?
Please reach out. We’re happy to help.
